Having set out to get a broader understanding of the container orchestration landscape. I decided to try the underdog of the solutions: HashiCorp's Nomad. Most new deployments favor Kubernetes, and many complain about its complexity. Nomad promises to be a simpler solution and it has HashiCorp's name behind it. It only requires one executable to run; Two if you deploy it alongside Consul.
All of the final code for this project and deployment instructions are available on GitHub and is tagged v1.0.0 . The master branch will continue to evolve as I add more features. https://github.com/ordenull/terraform-nomad-cluster/tree/v1.0.0
Introduction
The challenge is to build something that could host my blog, if I were to migrate it from DigitalOcean to AWS and over-engineer it to perfection. It currently costs roughly $35 a month for droplets (virtual machines) and another $5 for DNS hosting with DynDns. Let's see how much we can squeeze without blowing up our budget. Many enterprise projects start with an idea and a list of requirements, this one is not going to be any different.
Requirements
- Provisioned fully with Terraform
- Can be quickly torn down and rebuilt
- Running within a Virtual Private Cloud (VPC)
- Redundancy across multiple availability zones
- Everything built in auto-scaling groups
- Load balancer front-end with automatic instance registration
- SSL used on all external endpoints
- Easy access to the Nomad Dashboard
- Secure from the outside and from within
- Cost roughly $40 a month to operate
Virtual Private Cloud (VPC)
A traditional network architecture calls for a set of public and private subnets. The resources in the public subnets are assigned public IP addresses and communicate with the outside via a gateway. The private resources have to traverse Network Address Translation (NAT). In more restrictive infrastructures, the private resources do not have direct access to the outside networks at all. If they do, that traffic is heavily filtered via proxies and a whitelist maintained by a squad of network engineers.
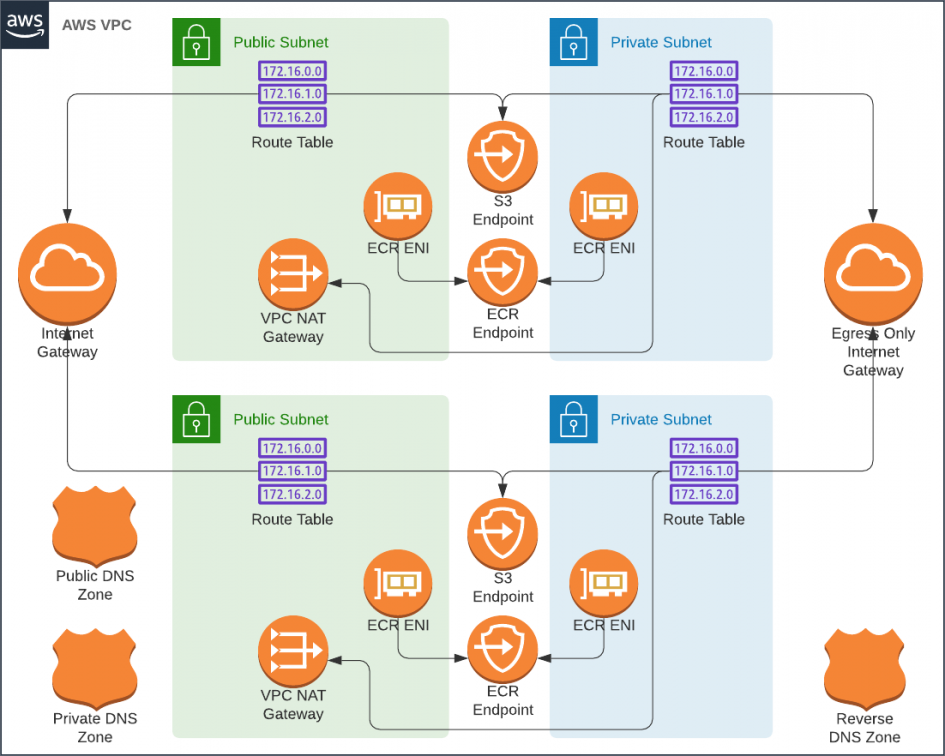
Estimate for a Traditional VPC With Two Availability Zones
- 1 ✕ VPC [$0]
- 2 ✕ Public Subnets [$0]
- 2 ✕ Private Subnets [$0]
- 3 ✕ Route53 Zones (public, private, reverse) [$2]
- 2 ✕ NAT Gateways [$66]
- 2 ✕ Private Link endpoints for S3 [$0]
- 2 ✕ Private Link endpoint for EC2 [$15]
- 2 ✕ Private Link endpoint for SSM [$15]
- 2 ✕ Private Link endpoint for ECR [$15]
Unfortunatley, this would cost a staggering $111 a month to lease; Way over our budget. We can't even afford a single NAT gateways, nor the private link endpoints. What if we were to use an Egress Only Internet Gateway to allow IPv6 connections to the outside world in place of NAT Gateways? I tried, and S3 and HashiCorp were accessible, but the rest of the AWS APIs only worked via IPv4 and would require private link endpoints.
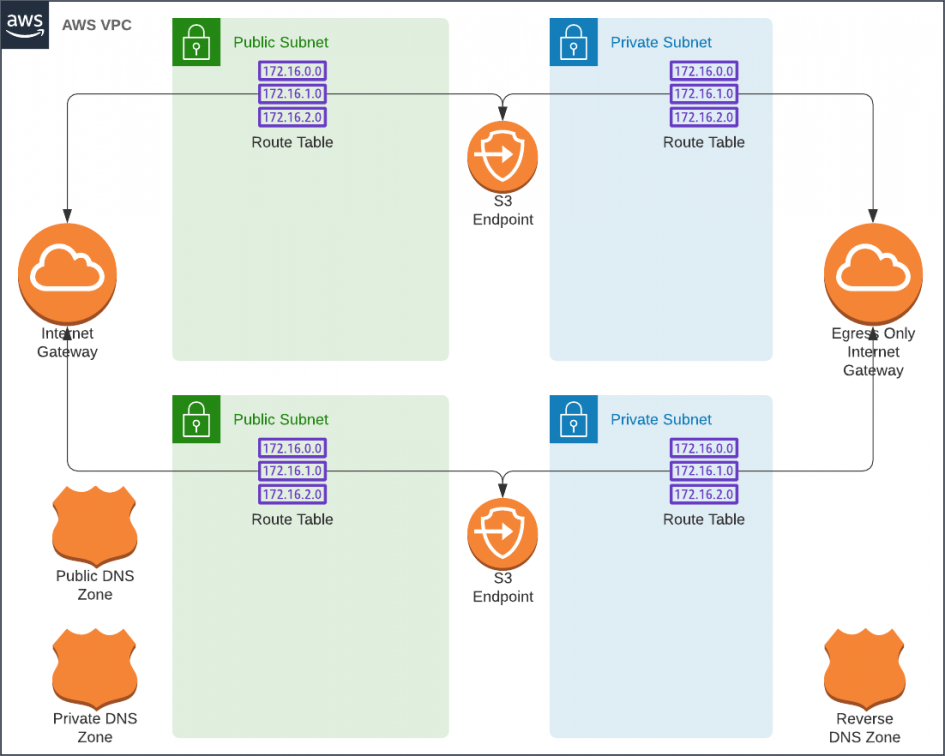
Services Accessible via IPv6 via
- ✓ Packages from amazonlinux.us-east-2.amazonaws.com (via S3 endpoint)
- ✓ Consul and Nomad from HashiCorp (via IPv6)
- ✗ SSM connectivity required as a substitute for a bastion [$15]
- ✗ EC2 endpoint required for nomad and consul node discovery [$15]
- ✗ ECR endpoint required to load Docker images [$15]
Although we can secure connectivity from the private subnets without NAT Gateways, The Private Link endpoints would still push us over our budget. It's to be noted that it is possible to deploy home baked NAT gateways hosted on t2.nano instances. However, I would rather spend the effort on building a transparent SSL MITM proxy for those subnets. Perhaps in a follow up article.
We're going to deploy our Nomad cluster in the public subnets and sleep easy because it will be protected from unauthorized access by security groups.
We will use a "default" security group to allow all egress from the subnet and to block all ingress except SSH from a list of trusted networks. This group will be attached to all instances in the subnet. Additional security groups will be used to allow various components to talk to one another. In other words, all internal and external connections to the EC2 instances will be blocked by default with exceptions that are required by Nomad's architecture.
Estimate for a Poor Man's VPC With Two Availability Zones
- 1 ✕ VPC [$0]
- 2 ✕ Public Subnets [$0]
- 2 ✕ Private Subnets [$0]
- 3 ✕ Route53 Zones (public, private, reverse) [$2]
- 2 ✕ Private Link endpoints for S3 [$0]
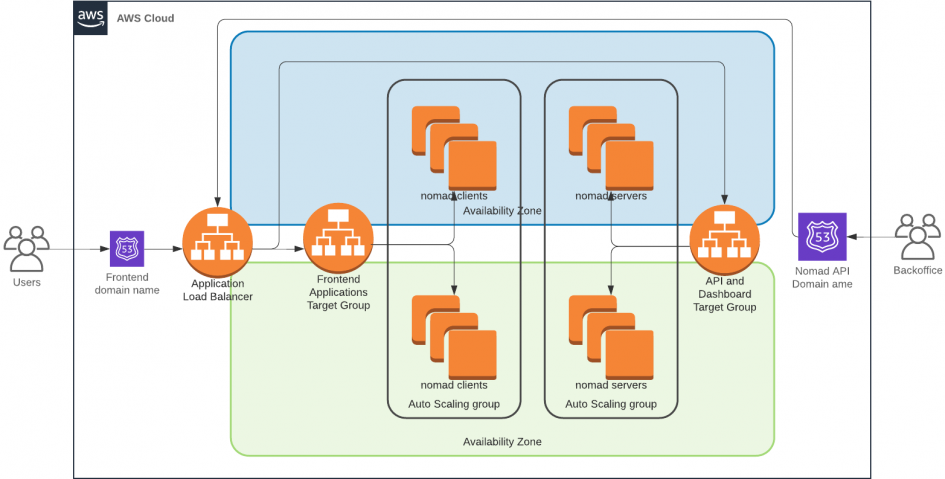
Nomad
Nomad reference architecture calls for three nomad servers that will be responsible for managing the cluster. A variable number of clients run jobs such as containers. The Nomad servers also expose an API that is used by Terraform to schedule jobs in the cluster. The dashboard is available from the same port.
Although Nomad servers are capable of running without Consul, I found that there's reliability gained with it running alongside. Both Nomad Servers and Nomad Clients will be placed in auto-scaling groups. This will allow me to easily tear the cluster down and re-create it without invoking Terraform. This approach does create a challenge for self-discovery of cluster instances. Each node that's created by the auto-scaling group will not have any information about other nodes that it can use to join the cluster. However both Nomad and Consul can query the EC2 API to discover instances with the same set of tags. We will rely on this.
Estimate for the Nomad Cluster Instances
- 3 ✕ t2.nano Nomad Servers [$12]
- 2 ✕ t2.micro Nomad Clients [$15]
Ingress
The next step in our journey is ingress. An Application Load Balancer is going to cost us about $16 a month. I wish it was cheaper, but it's going to be a reasonable purchase. The tradeoff would mean a lot more time spent building the same with Nginx or HA-Proxy. After-all, we need auto-scaling and automatic service registration. Those features would require quite a bit of development effort.
Because we will be relying on a single Application Load Balancer, we will have to somehow separate our private and public endpoints. Among other HTTP request attributes, the listener rules support matching the source IP address of the request. We will use this functionality to allow only our trusted networks to access the Nomad dashboard and the API. The public endpoints will match various virtual hosts and route them containers running on our Nomad clients.
It's important to note that this approach of securing Nomad will only work reliably if you have a static IP address. It also helps to have a VPN server that would allow roaming with that address.
Applications
To test it all, we will run a simple Hello World container. The code for deploying the container is tightly coupled with the infrastructure code and lives in the same codebase. This approach makes it easy to deploy auxiliary components such as Databases, ALB Target Groups and SSL certificates while minding dependencies.
Total Monthly Cost
- 1 ✕ VPC [$0]
- 2 ✕ Public Subnets [$0]
- 2 ✕ Private Subnets [$0]
- 3 ✕ Route53 Zones (public, private, reverse) [$2]
- 2 ✕ Private Link endpoints for S3 [$0]
- 3 ✕ t2.nano Nomad Servers [$12]
- 2 ✕ t2.micro Nomad Clients [$15]
- 1 ✕ Application Load Balancer [$16]
$45 + The cost of traffic
Conclusion
We have fulfilled most of our requirements and it has cost us about $45. However we haven't yet accounted for the data transfer costs nor for the Application Load Balancer usage LCU cost. For a large site, I highly recommend placing a CDN such as CloudFront or CloudFlare between the customers and the servers. With a CDN the traffic bill scales as favorably as the performance gain, but only if the content can be cached at the edge.
There are still a few items left lingering. Although our cluster supports auto-scaling, Nomad does not. Each Nomad job is configured to run with a pre-configured number of replicas. There are promises for an improved plugin API that would make it easier to address this deficiency. Meanwhile, I am looking at hooking Consul Watches (web-hooks) into Lambda Functions to accomplish this task.
Although we can now easily run stateless services, my blog is powered by WordPress. This platform requires state to be kept in a MySQL database and on the filesystem. Overcoming this within budget is going to be as big of a challenge as this cluster. Check back soon to see how I'll solve it.